1. FPGA
모든 FPGA 칩은 재구성 가능한 디지털 회로를 실행하기 위해 일정 갯수의 프로그래밍 가능한 커넥트를 가진 미리 정의된 리소스로 구성되어 있습니다.
[+] 크게 보기
그림1. FPGA의 각 부분

FPGA 칩 스펙은 슬라이스, 로직 셀과 같은 구성가능한 로직 블록 (CLB), 멀티플라이어와 같은 고정된 함수 로직, 및 임베디드 블록 RAM과 같은 메모리 리소스로 나뉩니다. 더 많은 요소들이 있지만 FPGA를 선택 및 비교할 때에는 지금 설명된 요소들이 가장 중요하게 여겨집니다.
가장 하위 레벨에 있는 CLB (슬라이스 및 로직 셀)는 두 개의 기본 요소 즉, 플립 플롭과 룩업 테이블 (LUTs)로 구성됩니다. 플립 플롭 및 LUT가 조합되는 방식에 따라 다양한 FPGA군은 서로 다른 아키텍처를 사용하기 때문에 이 두 가지는 중요합니다. Virtex-II FPGA에는 두 개의 LUT 및 두 개의 플롭 플롭이 있는 슬라이스가 있는 반면, Virtex-5 FPGA에는 4개의 LUT 및 4개의 플롭 플롭으로 구성된 슬라이스가 있습니다. LUT 아키텍처도 달라지며 (4개 입력 vs 6개 입력), LUT에 대한 더욱 자세한 내용은 차후에 살펴보겠습니다.
테이블 1은 LabVIEW FPGA 하드웨어 타겟에서 사용되는 FPGA의 스펙입니다. 일반적으로 게이트 갯수는 FPGA 칩과 ASIC 기술을 비교하는 방법으로 사용되었지만, 이것이 실제로 FPGA 내부의 개별 구성요소 갯수를 설명하지는 않습니다. 이것이 바로 Xilinx가 새로운 Virtex-5 제품군의 게이트 갯수를 명시하지 않은 이유입니다.
|
|
Virtex-II 1000 |
Virtex-II 3000 |
Spartan-3 1000 |
Spartan-3 2000 |
Virtex-5 LX30 |
Virtex-5 LX50 |
Virtex-5 LX85 |
|
게이트 |
1백만 |
3백만 |
1백만 |
2백만 |
----- |
----- |
----- |
|
플립 플롭 |
10,240 |
28,672 |
15,360 |
40,960 |
19,200 |
28,800 |
51,840 |
|
LUTs |
10,240 |
28,672 |
15,360 |
40,960 |
19,200 |
28,800 |
51,840 |
|
멀티플라이어 |
40 |
96 |
24 |
40 |
32 |
48 |
48 |
|
Block RAM (kb) |
720 |
1,728 |
432 |
720 |
1,152 |
1,728 |
3,456 |
테이블 1. 다양한 제품군을 위한 FPGA 리소스 스펙
본 스펙에 대한 이해를 위해 디지털 회로에 코드가 통합된 방식을 생각해 보십시오.
그래픽 또는 텍스트 방식에 상관없이 모든 통합가능한 코드에는 로직 블록이 어떻게 배선되었는지를 설명하는 해당 회로 도면이 있습니다. 간단한 불리언 로직을 살펴보고 해당되는 도식이 어떻게 나타나는지 확인하십시오. 그림 2는 5가지 불리언 신호를 채택하여 결과 이진값을 그래픽 방식으로 계산하는 함수 그룹입니다.

그림 2. 5가지 신호에 대한 간단한 불리언 로직
정상 조건 (LabVIEW 단일 주기 타임 루프 외부)하에서, 그림 2 블록 다이어그램의 결과로 나타나는 회로 도식은 그림 3과 같이 나타납니다.
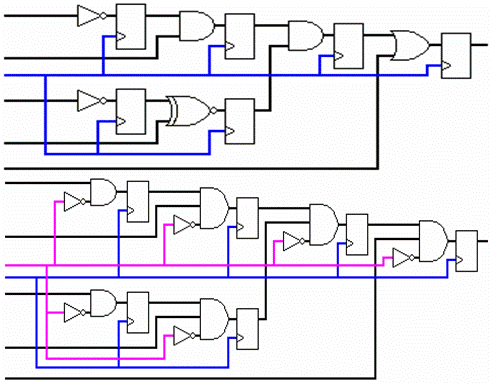
그림 3. 그림 2의 불리언 로직에 해당하는 회로 도식
그림에서 확인하기 어려울 수도 있지만 회로에 두 개의 병렬 가지가 생성되었습니다. 하나의 가지는 각 작업간의 동기화 레지스터를 추가하며, 두 번째 로직 체인은 데이터흐름 실행을 보장합니다. 총합 12개의 플립 플롭 및 12개의 LUT가 본 도식을 실행합니다. 상위 가지 및 각 구성요소는 다음 섹션에서 살펴보겠습니다.
2. 플립 플롭

그림 4. 플립 플롭 심볼
플립 플롭은 로직을 동기화하고 클럭 주기간 로직 상태를 저장하는 데에 사용되는 2진 시프트 레지스터입니다. 각 클럭 엣지에서, 플립 플롭은 입력에 대해 1 또는 0 (참 또는 거짓) 값을 래치하며 다음 클럭 엣지까지 값 상수를 유지합니다. 정상 상태하에서 LabVIEW FPGA는 모든 작동간 플립 플롭을 위치시켜 각 동작이 실행되기 위한 충분한 시간이 있는지를 확인합니다. 본 법칙에 대한 예외는 코드가 단일 주기 타임 루프 구조에 위치했을 때입니다. 특수 루프 구조에서는 플립 플롭이 루프 반복의 시작 및 끝에서만 추가되며, 타이밍 고려 사항을 이해하는 것은 프로그래머의 몫입니다. 단일 주기 타임 루프내에서 코드가 어떻게 통합되는 지에 대한 더욱 자세한 정보는 다음 섹션에서 살펴보도록 하겠습니다. 그림 5는 그림 3의 윗 부분이며, 플립 플롭이 붉은 색으로 표시되어 있습니다.

그림 5. 플립 플롭이 붉은 색으로 표시된 회로도 도면
3. 룩업 테이블 (LUTs)

그림 6. 4개 입력 LUT
그림 6에 나타난 회로 도식의 로직은 LUT 형태로 매우 소량의 RAM을 사용하여 실행됩니다. FPGA의 시스템 게이트의 수는 NAND 게이트 및 NOR 게이트를 의미한다고 판단하기 쉬우나, 실제로는 모든 조합 로직 (ANDs, ORs, NANDs, XORs 및 기타)은 LUT 메모리 내의 진리표로 실행됩니다. 진리표는 모든 입력 조합에 대한 미리 지정된 출력 목록입니다. (카르노도 맵- Karnaugh map이 어렴풋이 떠오를 것입니다.)
디지털 로직에 대해 다시 한번 환기해 보겠습니다.
한 예로 불리언 AND 연산을 그림 7에서 확인하실 수 있습니다.

그림 7. 불리언 AND 동작
테이블 2는 AND 작동의 두 개 입력에 대한 진리표입니다.
|
입력 1 |
입력 2 |
출력 |
|
0 |
0 |
0 |
|
0 |
1 |
0 |
|
1 |
0 |
0 |
|
1 |
1 |
1 |
테이블 2. 불리언 AND 작동에 대한 진리표
또한, 입력을 모든 출력에 대한 숫자형 인덱스라고 생각할 수도 있습니다. (테이블 3 참조)
|
LUT 인덱스 |
출력 |
|
0 (00) |
0 |
|
1 (01) |
0 |
|
2 (10) |
0 |
|
3 (11) |
1 |
테이블 3. 불리언 AND 동작 진리표 LUT 실행
Virtex-II 및 Spartan-3 FPGA에는 4개 입력 신호의 최대 16개 조합으로 진리표를 실행하기 위한 4개 입력 LUT가 있습니다. 그림 8은 4개 입력 회로 실행의 예입니다.

그림 8. 4개 입력 신호 회로 불리언 로직
테이블 4는 4개 입력 LUT내에서 실행하는 진리표입니다.
|
LUT 인덱스 |
출력 |
|
0 (0000) |
1 |
|
1 (0001) |
1 |
|
2 (0010) |
1 |
|
3 (0011) |
0 |
|
4 (0100) |
0 |
|
5 (0101) |
0 |
|
6 (0110) |
0 |
|
7 (0111) |
1 |
|
8 (1000) |
0 |
|
9 (1001) |
0 |
|
10 (1010) |
0 |
|
11 (1011) |
1 |
|
12 (1100) |
0 |
|
13 (1101) |
0 |
|
14 (1110) |
0 |
|
15 (1111) |
1 |
테이블 4. 그림 8 회로에 해당하는 진리표
Virtex-5 제품군의 FPGA는 6개 입력 LUT를 사용하며, 이는 6개의 서로 다른 입력 신호의 최대 64개 조합으로 진리표를 실행합니다. 플립 플롭간의 조합 로직이 매우 복잡하기 때문에 LabVIEW FPGA에서 단일 주기 타임 루프를 사용할 때 진리표는 매우 중요합니다. 다음 섹션에서는 LabVIEW에서 단일 주기 타임 루프가 FPGA 리소스 사용을 최적화하는 방법을 설명합니다.
4. 단일 주기 타임 루프
이전 섹션에서 사용된 예제 코드는 코드가 단일 주기 타임 루프의 외부에 위치하였다고 가정하였고, 또한 동시 데이터 흐름 실행을 보장하기 위하여 추가적인 회로를 통합하였음을 가정하였습니다. 단일 주기 타임 루프는 LabVIEW FPGA의 특수 구조로써 로직의 모든 가지가 단일 클럭 주기 내에서 실행됨으로 더욱 최적화된 회로 도식을 생성합니다. 예를 들어, 단일 주기 타임 루프가 40 MHz에서 작동하도록 구성된다면 모든 로직 가지들은 25 ns의 클럭 신호(clock tick)내에서 실행되어야 합니다.
이전 예제의 동일한 불리언 로직이 단일 주기 타임 루프 내에 위치한다면(그림 9) 생성되는 해당 회로 도식은 그림 10과 같이 나타납니다.

그림 9. 단일 주기 타임 루프내의 간단한 불리언 로직

그림 10. 그림 9의 불리언 로직에 해당하는 회로 도식
그림 3의 도식과 비교하면 본 실행이 더욱 간단하다는 것이 명백합니다. 플립 플롭간의 로직은 Virtex-5 FPGA (그림 11 참고)에서 최소 2개의 4개 입력 LUT를 요구합니다.

그림 11. 그림 10에서 회로 도식의 4개 입력 LUT 실행

그림 12. 그림 10에서 회로 도식의 6개 입력 LUT 실행
본 예제 (그림 9)에서 단일 주기 타임 루프는 40 MHz에서 실행되도록 구성되었고, 이는 로직이 한 번의 25ns클럭 내에서 실행되어야만함을 의미합니다. 코드가 실행되는 최대 속도는 회로를 통해 전자가 얼마나 전파되느냐에 따라 달라집니다. 가장 긴 지연시간을 가진 로직의 가지인 주경로는 회로의 특정 부분에 대한 이론적 최대 클럭 속도를 결정합니다. Virtex-5 FPGA의 6개 입력 LUT는 주어진 로직을 실행하기 위해 필요한 총 LUT 갯수를 줄여줄 뿐만 아니라, 해당 로직을 통한 전자의 전파 지연을 줄여줍니다. 따라서 Virtex-5-기반 하드웨어 타겟을 선택하기만 하면 더욱 신속한 클럭 속도를 위해 동일한 단일 주기 타임 루프를 구성할 수 있습니다.
Virtex-5 FPGA의 혜택에 대한 더욱 자세한 정보는 아래에 있는 기술 백서를 참조하십시오.
5. 멀티플라이어 및 DSP 슬라이스

그림 13. 곱하기 함수
두 개의 숫자를 곱하는 연산은 간단해 보이지만 극도로 리소스 집약적일 뿐 아니라 디지털 회로에 실행하기가 복잡합니다. 참조를 위해 그림 14에 조합 로직을 사용하여 4-비트 곱하기 4-비트 멀티플라이어를 실행하는 회로 도면이 있습니다.

그림 14. 4-비트 x 4-비트 멀티플라이어 회로도 도면
두 개의 32-비트 숫자를 곱하려면 결국 단일 곱하기를 2000번 이상 수행해야 합니다. 이 때문에 FPGA에는 미리 내장된 멀티플라이어 회로가 있어 수학 및 신호 프로세싱 어플리케이션에서 LUT 및 플립플롭 사용을 절약할 수 있습니다. Virtex-II 및 Spartan-3 FPGA에는 18-비트 x 18-비트 멀티플라이어가 있으므로 2개의 32-비트 숫자를 곱하기 위해 세 개의 멀티플라이어가 필요합니다. 여러가지 신호 프로세싱 알고리즘에는 곱해지는 총 수 확인이 포함되어 있기 때문에, 그 결과로 Virtex-5와 같은 고성능 FPGA에는 DSP 슬라이스라고 불리는 미리 구축된 멀티플라이어-어큐뮬레이터 (MAC) 회로가 있습니다. 그림 15는 MAC(multiply-accumulate) 함수를 사용한 블록 다이어그램입니다.

그림 15. Multiply-Accumulate(MAC) 함수 사용 예
DSP48 슬라이스로 알려진 미리 구축된 프로세싱 블록에는 25-비트x 18-비트 멀티플라이어 및 가산기 회로가 있습니다. 물론, 멀티플라이어 기능을 독립적으로 사용할 수도 있습니다. 테이블 5는 다양한 FPGA 제품군을 위한 DSP 리소스입니다.
|
|
Virtex-II 1000 |
Virtex-II 3000 |
Spartan-3 1000 |
Spartan-3 2000 |
Virtex-5 LX30 |
Virtex-5 LX50 |
Virtex-5 LX85 |
|
멀티플라이어의 |
40 |
96 |
24 |
40 |
32 |
48 |
48 |
|
유형 |
18x18 |
18x18 |
18x18 |
18x18 |
DSP48 슬라이스 |
DSP48 슬라이스 |
DSP48 슬라이스 |
테이블 5. 다양한 FPGA를 위한 DSP 리소스
6. Block RAM (BRAM)
메모리 리소스는 FPGA를 선택할 때 고려해야 할 주요 스펙입니다. 사용자 정의된 RAM은 FPGA 칩을 통해 임베디드되어 있으며, 데이터 세트를 저장 또는 병렬 루프간 값을 전달하기에 유용합니다. FPGA 군에 따라, 16 또는 36 kb의 온보드 RAM을 구성할 수 있습니다. 또는 플립 플롭을 사용하여 데이터 세트를 어레이로 실행할 수도 있습니다. 그러나, 대형 어레이는 FPGA 로직 리소스에 사용하기에 비용이 많이 필요합니다. 32-비트 숫자의 100개 원소 어레이는 Virtex-II 1000 FPGA에서 30퍼센트 이상의 플립 플롭을 사용하거나, 임베디드 블록 RAM의 1퍼센트 미만을 차지합니다. DSP 알고리즘은 종종 데이터의 전체 블록을 추적 또는 복합 방정식의 계수를 추적하는데 필요로 합니다. 온보드 메모리가 없는 경우, 많은 함수 처리는 FPGA 칩의 하드웨어 로직으로 적합하지 않습니다. 그림 16은 블록 RAM을 사용하여 메모리를 읽거나 쓰는 그래픽 함수를 보여줍니다.
[+] 크게 보기
그림 16. 메모리에 쓰거나 읽기 위한 Block RAM 함수

또한 하나의 완벽한 주기를 값 테이블로 저장하고 테이블을 통해 순차적으로 인덱스함으로써 온보드 신호 생성에 대한 주기적 웨이브폼 데이터를 저장하기 위해 메모리 블록을 사용할 수 있습니다. 출력 신호의 최종 주기는 값이 인덱스화되는 속도에 따라 결정되며, 웨이브폼에서 가파른 변화없이 출력 주기를 다이나믹하게 변경하기 위해 본 방식을 사용할 수 있습니다.
[+] 크게 보기
그림 17. FIFO 버퍼를 위한 BRAM 함수

FPGA 고유의 병렬 실행은 하드웨어 로직의 개별 부분이 서로 다른 클럭에 의해 구동되는 것을 가능하게 합니다. 서로 다른 속도로 실행되는 로직간 데이터를 전송하는 것은 매우 까다로워서, 온보드 메모리는 종종 first-in-first-out (FIFO) 버퍼를 사용하여 전송을 원활히 하는 데에 사용됩니다. 그림 17에서와 같이 FIFO 버퍼를 서로 다른 크기로 구성할 수 있으며, FPGA 칩의 비동기 부분간에 데이터 손실이 없도록 할 수 있습니다. 테이블 6은 다양한 FPGA 군에 임베디드된 사용자 구성가능한 Block RAM입니다.
|
|
Virtex-II 3000 |
Virtex-II 1000 |
Spartan-3 1000 |
Spartan-3 2000 |
Virtex-5 LX30 |
Virtex-5 LX50 |
Virtex-5 LX85 |
|
총 RAM (kbits) |
1728 |
720 |
432 |
720 |
1152 |
1728 |
3456 |
|
블록 크기 (kbits) |
16 |
16 |
16 |
16 |
36 |
36 |
36 |
테이블 6. 다양한 FPGA를 위한 메모리 리소스
7. 결론
High level 툴이 더욱 발전되고 여러 개념을 추상화함에 따라 FPGA 기술 채택이 계속해서 증가하고 있습니다. 그러나 FPGA의 내부를 이해하는 것과 블록다이어그램이 컴파일되어 실리콘칩에서 실행될 때 얼마만큼이 실질적으로 일어나는지를 이해하는 것은 여전히 중요합니다. 리소스 사용 및 최적화에 대해 이해하고 있는 사용자라면 플립 플롭, LUTs, 멀티플라이어, BRAM에 기반한 하드웨어 타겟을 비교하고 선택하시면 개발 기간 동안 도움이 될 것입니다. 이 기본적인 빌딩 블록은 리소스 모두를 의미하는 것은 아닙니다. 본 기술백서에서 다루지 않은 기타 여러 FPGA 구성요소는 아래의 다른 리소스에서 살펴보실 수 있습니다.