
이 식에서 g[n+m] 부분이 Template Matching에서 중요한 의미를 갖는데, 바로 Cross Correlation이 Convolution으로부터
유래하기 때문이다.
Convolution 계산 식은 아래와 같다.

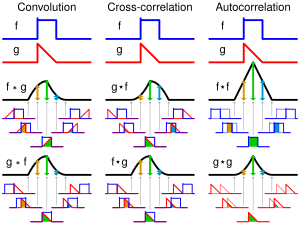
위 식을 살펴보면, f* 부분과 함께 g[n-m], 즉 방향이 반대인 것을 확인할 수 있다. 다시 말해 cross correlation은 kernel 함수 g를 convolution과 반대 방향으로 입력한다. 이를 시각화 하면 아래와 같다(맨 밑에 있는 그림에 주목).
영상과 같이 신호가 2차원으로 해석될 때 Convolution을 구하는 식은 아래와 같다.

정의 상 b(n1-k1, n2-k2) 가 필요한데, k1, k2가 0보다 클 때 즉, b(-1, -1) 등은 정의되지 않는다(아래 식에서는 y[0]일 때를 보라).
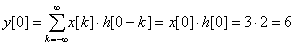
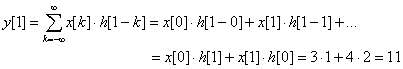
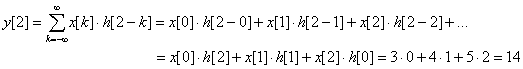
위 식에서 주목할 점은 x 값과 곱해지는 h 값이 원래 값에 비해 상하좌우로 뒤집혀진다(flip)는 점이다.
즉, 그림으로 표현하면 아래와 같다.
즉, 그림으로 표현하면 아래와 같다.
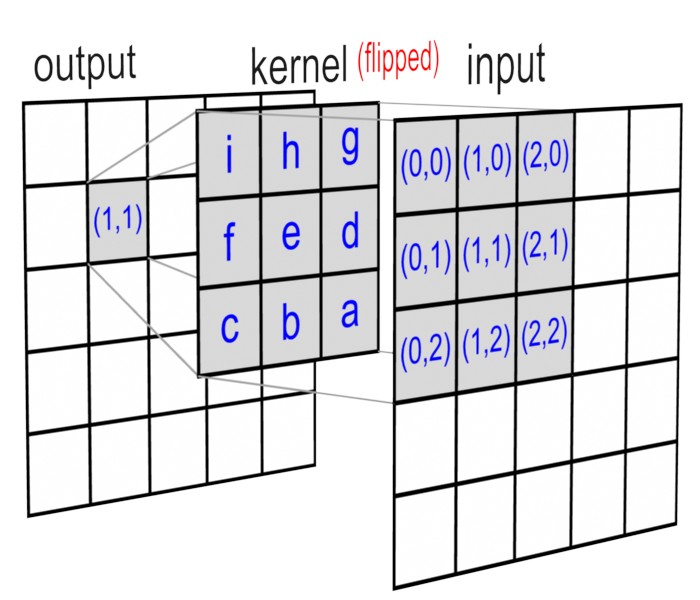
때문에 이 결과를 영상으로 해석하면 flip된 template 영상의 각 픽셀을 input 영상을 곱하고 더하는 것이 된다.
만약 Input 된 영상 위에서, flip된 template과 완전히 같은 부분이 있다면, 각 픽셀들이 제곱되어 더해지므로 값이 매우 커지게 된다.
만약 Input 된 영상 위에서, flip된 template과 완전히 같은 부분이 있다면, 각 픽셀들이 제곱되어 더해지므로 값이 매우 커지게 된다.
그렇다면 cross correlation은 어떨까? 영상으로 해석하자면 cross correlation은 template 영상(flip 되지 않는다)의 픽셀들을 input 영상 위에서 곱하고 더하는 결과가 된다. 즉, input 영상에서 template 영상이 정확히 매치되는 곳이 있다면, 해당 위치에서 cross correlation 값이 매우 커지게 된다.
아래는 간단한 matrix로 그 예를 보인다.


위와 같이 원본 영상에 해당하는 Matrix a가 있고, 오른 쪽 구석에 해당하는 template b가 있다고 하자. 그리고 이 둘의 convolution을 구해보면(MATLAB) 아래와 같다.

위에서 보다시피, convolution의 가장 큰 점이 왼쪽 상단 구석으로 잡히는 것을 알 수 있다. 그렇다면 cross correlation을 구하면 어떨까?
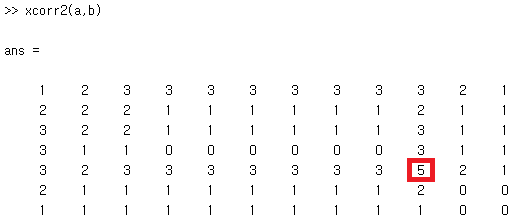
보다시피, 기대한 오른쪽 구석에서 가장 높은 값이 나오는 것을 알 수 있다.
여기서 잠깐 살펴볼 것은 convolution의 결과 크기가 input보다 큰 것이다. 이것은 convolution의 정의상 그 크기가 [두 matrix의 크기 합 - 1]이기 때문이다. 따라서 이 결과 상에서는 바로 template matching point를 정의할 수 없다. convolution 결과를 input 영상의 자표로 변환해야 하는데, 간단히 input 에서 padding 된 size 의 절반 만큼만 빼주면 된다. 즉, 그림으로 나타내면 아래의 범위가 Input 영상의 범위가 된다.

그리고, matching point(즉, maximum value가 나온 지점)은 template의 중심점이다. 따라서 matching 영역의 시작점을 구하기 위해서는 template size의 절반 만큼 씩 matching point에서 빼줘야 한다.
Cross correlation을 통한 template matching의 장점은 속도에 있다. convolution 연산을 주파수 도메인에서 계산하면 간단한 곱 연산만 있기 때문에 FFT를 이용하면 매우 빠른 속도로 계산을 수행할 수 있다(아래 식 참조).
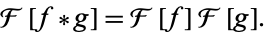
cross correlation 또한 conjugation이 추가된다는 점을 빼고는 convolution과 똑같이 수행된다. 때문에 속도가 굉장히 빠르다.
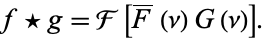
하지만, 매우 큰 단점이 있는데, 단순히 매칭 영역 내 픽셀들의 곱을 더한 것으로 매칭 정도를 측정하다보니, illumination 상태에 따라 성능이 매우 달라진다(input 영상에서 흰점이 몰려 있는 곳에서는 어느 템플릿도 matching point가 높아진다). 이를 보완하기 위해 normalize를 하기도 하는데, 도메인에 따라서는 적용이 불가능한 곳도 있다.
참고 사이트